4. レポートd(深層学習Day3、Day4)
【深層学習Day3】
Section1:再帰型ニューラルネットワークの概念
- 要点のまとめ
RNN(Recurrent Neural Network)とは時系列データに対応可能な、ニューラルネットワーク(以下、N.N.と表記)である。時系列モデルを扱うため、初期の状態と過去の時間t-1の状態を保持し、そこから次の時間tを再帰的に求める再帰構造を持つ。
パラメータの更新はBPTT(Back Propagation Through Time)により行う。
- 実装演習結果キャプチャー又はサマリーと考察
3_1_simple_RNN_after.ipynbの実行結果を表示する。
<simple RNN after, バイナリ加算>
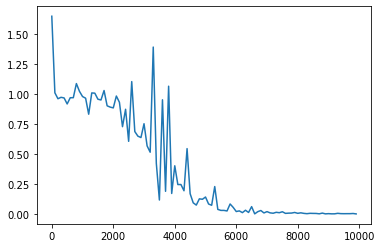
図;ウェイト初期化を乱数で実施
<simple RNN after, バイナリ加算、Heによるウェイト初期化>
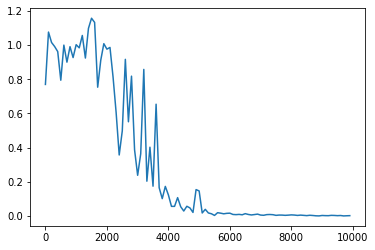
図:ウェイト初期化をHeで実施
前の図と比べると、収束が若干早いことが観測される。
- 「確認テスト」など自分の考察結果
<確認テスト1;RNNネットワークの3つの重み>
一つ目は入力から現在の中間層に対する重み(W(in))
二つ目は中間層から出力に対する重み(W(out))
三つめが一つ前の状態から今の状態に対する重み(W)
である。
<確認テスト2:連鎖律の原理でdz/dxを求める>
以前実施済みの復習問題につき、省略。
<確認テスト3:RNNの出力を表す式>
y = g( Wout・S1 +c), s1 = f( Win・x1 + w・s0+b)
プログラムの再帰構造部分を下に示す。(プログラム上は、配列の添え字が0からカウントされることから、t-1がt、tがt+1として記載される)

中間層への入力uと中間層からの出力zには、一つ前の値が代入されている。
- 演習問題や参考図書、終了課題など関連記事レポート
<演習チャレンジ1>
木構造は再帰的な辞書で定義されており、rootが最も外側の辞書であると仮定した場合の
活性化関数は、_activation(W.dot(np.concatenate([left,right])))である。
木構造の2つの要素を連結する。
<演習チャレンジ2>
calculate_dout関数が損失関数を出力に関して偏微分した値を返す関数であるとすると、
delta_t = delta_t.dot(U)となる。(過去に遡るたびにUが掛けられる)
<演習チャレンジ3>
RNNや深いモデルでは勾配の消失や爆発を防ぐために勾配のクリッピングを行うという手法がある。勾配のノルムがしきい値を越えたら、勾配のノルムをしきい値に正規化するというものであり、
rate = threshold / norn
if rate < 1:
return gradient*rate
となる。(nornがthresholdを越えた場合に、thresholdに制限する)
Section2:LSTM
- 要点のまとめ
RNNは時系列を遡るほど、勾配が消失するという課題があるが、構造自体を解決したものがLSTM(Long Short Time Memory)である。RNNの自己ループを持つ中間層に代わり、LSTM Blockが配置される。LSTMは入力ゲート、忘却ゲート、出力ゲート及びCEC(Constant Error Carousel)を持つことが特徴である。
LSTMのバリエーションの一つとして、覗き穴結合がある。効果はあまりないようである。
- 実装演習結果キャプチャー又はサマリーと考察
サンプルプログラムが無かったので、代わりに実装方法を調べた。
LSTMはKerasにより、実装が容易である。Keras DocumentationのRecurrentレイヤーを参照すると、次のモジュールにて利用が可能である。
keras.layers.LSTM(units, activation=’tanh’, recurrent_activation=’hard_sigmoid’, use_bias=True, kernel_initializer=’glorot_uniform’, recurrent_initializer=’orthogonal’, bias_initializer=’zeros’, unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0, implementation=1, return_sequences=False, return_state=False, go_backwards=False, stateful=False, unroll=False)
- 「確認テスト」など自分の考察結果
<確認テスト:文章を入力したとき、あってもなくても良いことばに採用するゲート>
例文「映画おもしろかったね。ところで、とてもお腹が空いたから何か………….。」
この文章で「とても」は空欄の予測には重要でない。
=> LSTMにある3つのゲートのうち、「忘却ゲート」が作用する。
- 演習問題や参考図書、終了課題など関連記事レポート
<演習チャレンジ:LSTMの順伝搬のプログラム>
CECの入力は、input_gateとforget_gateである。この地点で答えは(3)か(4)に絞られる。また、一つ前のCECの値が掛け合わされるのは、forget_gateなので、forget_gate・cとなるので、答えは(3)となる。
Section3:GRU
- 要点のまとめ
LSTMの構造が複雑で計算コストがかかるという欠点があるので、それを改良したものがGRU(Gated Recurrent Unit)である。GRUではCECは不要とし、3つのゲート(入力ゲート、忘却ゲート、出力ゲート)の代わりに、2つのゲート(リセットゲート、更新ゲート)が配置される。GRUでは隠れ層で、前の状態を記憶させる。
- 実装演習結果キャプチャー又はサマリーと考察
Predict_word.ipynbの実行結果を表示する。

図:実行結果
tensorflow_version1.xにて、実行した。
Tensorflowだと、実装が容易である。本プログラムではBasic RNNを利用した。
- 「確認テスト」など自分の考察結果
<確認テスト:LSTMとCECが抱える課題>
LSTMは、3つのゲートとCECを持つ、複雑な構成によりパラメータが多く、計算コストがかかることが課題である。CECは勾配が1で学習能力がないため、入力ゲートと忘却ゲートと接続することで学習機能を持たせている。この点も計算コストがかかる要因の一つである。
<確認テスト:LSTMとGRUの違い>
一番のポイントは複雑さの違いで。GRUはLSTMよりも簡略化された構造とすることで、計算コストを抑えている。
- 演習問題や参考図書、終了課題など関連記事レポート
<演習チャレンジ:GRUの順伝搬プログラムのプログラムについて>
次状態hの計算部分を選択する。
r:リセットゲートからの出力、z:更新ゲートからの出力。x:入力
GRUの全体像の図より、
h(t) = f(z(t)・h(t-1)+(1-z(t))・h(t)である。 (f:活性化関数)
この式を踏まえると、h_barがh(t-1)をあらわし、h_newは
(4) (1-z)*h+z*h_bar が回答となる。
Section4:双方向RNN
- 要点のまとめ
双方向RNNとは、過去の情報だけでなく、未来の情報を加味することで、精度を向上させるためのモデルで、実用例としては、文章の推敲や機械翻訳等があげられる。
RNNの中間層は、過去から未来に向けての方向でつながっていたが、双方向RNNでは、未来から過去につながった、中間層をもう一つ追加した構造となっている。
- 実装演習結果キャプチャー又はサマリーと考察
実装演習が無かったので、双方向RNNの実装方法を調べた。
tensorflowのライブラリにて実装ができる。
#Bidirectional(双方向RNN)
from tensorflow.keras.layers import Embedding, Dense, Bidirectional, LSTM
model = keras.Sequential()
- 「確認テスト」など自分の考察結果
<bnnのプログラムを問題から抜粋し理解を深めた>
def brnn(xs, W_f, W_in_f, W_b, W_in_b, W_out):
‘’’
xs:入力値
W_f:順方向の隠れ層から隠れ層への重み
W_in_f:順方向の入力層から隠れ層への重み
W_b:逆方向の隠れ層から隠れ層への重み
W_in_b:逆方向の入力から隠れ層への重み
W_out:隠れ層から出力層への重み
‘’’
hs_f = _rnn(xs, W_f, W_in_f) #順伝搬
hs_b = _rnn(xs[::-1], W_b, W_in_b) #逆伝搬
hs = [np.concatenate([h_f, h_b[::-1], axis=1]) for h_f, h_b in zip(hs_f, hs_b)] #結合
ys = np.dot(hs, W_out.T)
return ys
- 演習問題や参考図書、終了課題など関連記事レポート
<演習チャレンジ:双方向RNNのプログラム>
入力から中間層への重み:W_f
一ステップ前の中間層出力から中間層への重み:U_f
逆方向の重み:W_b
一ステップ前の逆方向の重み:U_b
両者の中間層から合わせた重み。
=>足し算、掛け算だと情報が消えてしまう。基本は連結となるので、(3)か(4)である。
(3)と(4)の違いは、列に沿った処理axis=0であるか、行に沿った処理axis=1であるかである。今回の場合は、双方向の中間層表現を合わせたものが特徴量となるため、axis=1の(4)が回答となる。
Section5:Seq2Seq
- 要点のまとめ
Seq2SeqはRNNによる自然言語処理用のネットワーク処理の一つである。
Encoder-Decoderモデルの1種であり、機械対話や機械翻訳に使用されている。
EncoderとDecoderは別々のRNNで構成されている。Encoder RNNに単語列を入力していくと、それまでに入力された記憶により文脈が保持される。Decoder RNNでは、EncoderRNNで保持されている文脈をもとに、翻訳結果を出力させる。
Seq2Seqでは1文一答しかできないという課題があるが、
HREDでは、過去n-1個の発話から次の発話を生成する。
HREDの構成は、Seq2Seq+ContextRNNである。
HREDの課題としては、情報量の少ない答えをしがちとなる。
これの対策を図ったものが、VHREDである。
- 実装演習結果キャプチャー又はサマリーと考察
URL https://www.pytry3g.com/entry/pytorch-seq2seq#%E7%92%B0%E5%A2%83
にあったseq2seqのプログラムをgoogle colaboratory上で実行した。(pytorch)
20,000語をバッチサイズ100、Epoch100で学習
<学習>
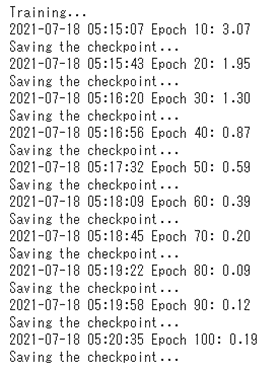
図:学習結果(参考)
<テスト>

100Epochで7割程度であった。
図:精度(参考)
- 「確認テスト」など自分の考察結果
<確認テスト:seq2seqの正しい説明>
(1)は、双方向RNNの説明である。
(2)がseq2seqの説明である。(RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
(3)構文木の説明である。
(4)はLSTMの説明である。
<確認テスト:VAEに関する説明>
VAEは、自己符号化器の潜在変数に確率分布を導入したものである。
(確率分布z~N(0,1)を仮定)
<確認テスト:seq2seqとHRED、HREDとVHREDの違い>
seq2seqは一問一答により、ある時系列データからある時系列データを生成する。
HREDはseq2seqの機構にそれまでの文脈の意味ベクトルを解釈に加えられるようにすることで、文脈の意味をくみ取ったEncodeとDecodeを行うことが出来る。
HREDが文脈に対して、情報量の少ない当たり障りのない回答しかつくれなくなった場合の解決策であり、VAEのオートエンコーダーの考えを取り入れて、短い当たり障りのない表現以上の出力が得られるよう改良したものである。
- 演習問題や参考図書、終了課題など関連記事レポート
<演習チャレンジ:encodeのプログラム>
入力は複数の単語からなる文章、それぞれの単語はone-hotベクトルで表現されている。
ここでeはword_embedding_matrixである。eの適切なプログラムを選択する。
=>文の意味を表すベクトルは単語に対するドット積を取る。(1)が答え。
Section6:Word2vec
- 要点のまとめ
RNNでは、単語のような可変長の文字列をNNに与えることができない。つまり、固定長形式で単語を表す必要がある。Word2vecは単語をベクトル表現にする手法である。(単語→ID->one-hot->embedding)
- 実装演習結果キャプチャー又はサマリーと考察
Word2vecの実装手法としては、skip-gram法やCBOWの仕組みが有名である。skip-gram法は、中心語から周辺の単語を予測する手法である。CBOWは周辺の単語から中心語を予測する手法である。用途としては、チャットボット、感情分析、文章要約などが上げられる。
- 「確認テスト」など自分の考察結果
<確認テスト:RNNとword2vecの違い>
RNNは時系列データを処理するのに適したNNである。NNに回帰構造を持たせている。word2vecは単語の分散表現ベクトルを得る手法である。コンテキストを入力層に入れ、中間層から出力層でスコア=>確率=>成果ラベルを得る仕組みである。
- 演習問題や参考図書、終了課題など関連記事レポート:なし
Section7:Attention Mechanism
- 要点のまとめ
seq2seqは長い文書への対応が難しいという課題がある。2単語でも100単語でも、固定次元ベクトルの中に入力しなければならない。従って、文章が長くなるほどそのシーケンスの内部表現の次元も大きくなる仕組みが必要である。これを解決するのが、Attention Mechanismであり、「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組みである。
- 実装演習結果キャプチャー又はサマリーと考察:なし
- 「確認テスト」など自分の考察結果
<確認テスト:seq2seqとAttentionの違い>
seq2seqは一つの時系列データから別の時系列データを得るニューラルネットワークである。seq2seqでは、入力系列の情報をEncoderで圧縮してから、Decoderに伝えるため、入力系列が長い場合には、Decoderに伝わりにくいとの問題がある。Attention Mechanismはその問題に対処するため、時系列データの中身のそれぞれの関連性に重みをつける手法である。seq2seq+attentionという使われ方をする。
- 演習問題や参考図書、終了課題など関連記事レポート:なし
【深層学習Day4】
Section1:強化学習
- 要点のまとめ
今までに学んだ、教師あり学習、教師なし学習に加え、もう一つのカテゴリーが強化学習である。これまでの教師あり学習、教師学習は平たく言うと、データの特徴を見つけるものである。一方、強化学習は、行動の結果として与えられる利益(報酬)をもとに行動を決定する原理を改善していく仕組みである。
- 実装演習結果キャプチャー又はサマリーと考察
強化学習の中で、関数近似法とQ学習が重要な概念である。
関数近似法は、価値観数や方策関数を近似する手法である。従来は、条件に応じて処理を選んでいたが、それを関数とすることで、統一的に扱うことでき、強化学習の進展につながった。
価値観数は、エージェントに対する価値の決め方により、状態価値観数と行動価値関数の2種類がある。ある状態によってのみエージェントに対する価値が決まる場合には、状態価値観数。状態と価値の両方によってエージェントに対する価値が決まる場合には、行動価値観数が用いられる。
方策関数は、方策ベースの強化学習において、ある状態でどのような行動をとるのかの確率を与える関数である。
- 「確認テスト」など自分の考察結果
<確認:強化学習と通常の教師あり・なし学習との違い>
目的、目標が異なる。
教師なし、教師あり学習であはデータの「特徴を見つけたり」、データから「予測」を行うことが目的であるが、強化学習では「優れた方策」を見つけることが目的となる。
- 演習問題や参考図書、終了課題など関連記事レポート:なし
Section2:AlphaGo
- 要点のまとめ
AlphaGoは、Google Deepmind社によって開発された囲碁対局用のAIプログラムでる。2015年に人間のプロ棋士に勝利したことから、強化学習が注目を集めることとなった。
AlphaGoの入力は、囲碁の盤面にあわせて、19x19次元の配列である。
Policy Netで、人間の棋譜を学び、どこに石を置くかの情報を得る。また、Value Netでは、
では、石を置いた場合の対局シミュレーションを行い、勝率の高い手を選ぶ。
AlphaGoにはAlpha Go Lee やAlpha Go Zeroといったバリエーションがあるが、Alpha Go Zeroでは、棋譜による学習を行わず、ルールだけを教え、自己対戦により学習を行わせる。
- 実装演習結果キャプチャー又はサマリーと考察:なし
- 「確認テスト」など自分の考察結果:なし
- 演習問題や参考図書、終了課題など関連記事レポート:なし
Section3:軽量化・高速化技術
- 要点のまとめ
コンピュータの性能は18ヵ月~24ヵ月で性能が倍になるのに対し、現在の深層学習ではモデルが複雑化し、1年に10倍のベースで扱うデータ量が増えており、そのギャップを埋めていく必要がある。
軽量化・高速化技術の目的は2つある。一つ目は、いかにモデルを高速に学習させるか、学習期間の短縮が目的である。従来1週間かかっていたものを1日で終わらせるようなことを目指すものである。これらの技術としては、モデル並列、データ並列、GPUなどが上げられる。
もう一つが、毎回モデルを動かすために、高性能なコンピュータに頼るのではなく、計算能力の低いコンピュータで必要性能を得ることを目的とするものである。その技術としては、量子化、蒸留、プルーニングが上げられる。
- 実装演習結果キャプチャー又はサマリーと考察
<各技術のサマリー>
・データ並列化
親モデルを各ワーカー(コンピュータ)に子モデルとしてコピー。
データを分割し、各ワーカーごとに計算させる。
データ並列化は、各モデルのパラメータの合わせ方で、同期型か非同期型かきまる。
同期型の場合は、各ワーカーの計算が終わるのをまって、全ワーカーの勾配が出た
ところで勾配の平均を計算し、親モデルのパラメータを更新する。
非同期型の場合は、各ワーカーはお互いの計算を待たず、各個モデルごとに更新を行い、
パラメータサーバに学習済み子モデルをPUSHしていく。
非同期型の方が、全体の処理は早くなるが、不安定になりやすく、精度優先で同期型が
主流である。
・モデル並列化
親モデルを縦方向なり横方向で分割して、各ワーカに分割する。モデルの
パラメータ数が多いほど、スピードアップの効率も向上する。
・GPU
コンピュータには、CPUやグラフィック用のGPUといった演算装置があるが、深層学習の演算は単純な行列演算が多く、これをコンピュータのCPUだけでやらせるのは効率が悪い。これまでに、グラフィック表示に必要な単純な計算をGPUやらせていたように、機械学習で必要な単純な演算はGPUにやらせる方が効率的である。機械学習の発展に伴い、GPUは、元々の使用目的であるグラフィック以外の用途で使用されるGPGPU(General-purpose on GPU)として利用されるようになってきた。
GPGPUの開発環境としては、NVIDIAのGPUのみで使用可能なCUDAが有名である。
・量子化
ネットワークが大きくなると大量のパラメータが必要となり、学習や推論に多くの目盛りと演算処理が必要である。パラメータの64bit浮動小数点を32bitなど下位の精度におとすことでメモリと演算処理の削減を行う。
ニューロンの重みの浮動小数点の有効数字を下げることは、多くのメモリを消費するモデルのメモリ使用量の低減につながる。
演算高速化と省メモリ化のメリットに対し、精度の低下というデメリットがあるが、倍精度から単精度に落としたくらいでは、ほぼ精度が変わらないことが知られている。
・蒸留
精度が高く規模の大きいモデルから、軽量なモデルを作ることである。
蒸留は教師モデルと生徒モデルの2つで構成される。
教師モデルは予測精度の高い学習済みのモデルである。教師モデルの重みを固定し、並列に接続した生徒モデルの重みを更新していく。教師モデルと生徒モデルの誤差を最小化するように学習させることで、生徒モデルは教師モデルの特徴を引き継ぐこととなる。
・プルーニング
寄与の少ないニューロンの削減を行いモデルの圧縮を行うことで、軽量化と高速化を図るものである。手法としては、重みがしきい値以下の場合には該当のニューロンを削除し、再学習を行わせる。全結合層全体のパラメータの94%削減しても90%以上の精度が得られた事例も紹介されている。
- 「確認テスト」など自分の考察結果
<データ並列化;同期型と非同期型の違い>
<データ並列化とモデル並列化の使い分け>
モデルが大きいときはモデル並列化をデータが大きいときはデータ並列化を
選択するのが良い。また、複数のコンピュータに分けるときは、データ並列化、
1台のコンピューターに接続した複数のGPUボードを使う場合には
モデル並列化が良い。
- 演習問題や参考図書、終了課題など関連記事レポート
動画講義で取り上げていた論文を参照したところ、
32bitから6bitに量子化しても精度が大きく落ちないとの結果であった。
<論文>
Penghang Yin, Shuai Zhang, Yingyong Qi, and Jack Xin(2017) 「Quantization and Traning of Low Bit-Width Convolutional Neural Networks for Object Detection」, https://arxiv.org/pdf/1612.06052.pdf
表:量子化と精度 (上記論文より抜粋)


図:画像認識結果(32bitと6bit) (上記論文より抜粋)
Section4:応用モデル
- 要点のまとめ
講義で取り上げられた応用モデルを以下に記す。
・MobileNet
画像認識モデルは精度面では2017年で実用化レベルに達した。
以降は、軽量化を目指す動きである。
MobileNetは軽量化を図った画像認識モデルである。
畳み込み演算で工夫を行っている。
Depthwise ConvolutionとPointwise Convolutionの組み合わせで軽量化を実現
Depthwise Convolutionではフィルタサイズを1に固定。入力のチャンネルごとに
コンボリューションを行う。
Pointwise Convolution では、カーネル1x1xCでconvolutionを行う。
・DenseNet
画像認識のモデルである。
計算機性能の向上にあわせ、認識精度向上を目的にネットワークの層も深まった。
一方、層が深いと勾配消失問題により学習がうまくいかないケースが出てきた。
層をスキップして接続する構成により勾配消失問題に対処したものがDenseNetである。
同様の発想で先にResNetが登場しており、DenseNetはその改良モデルである。
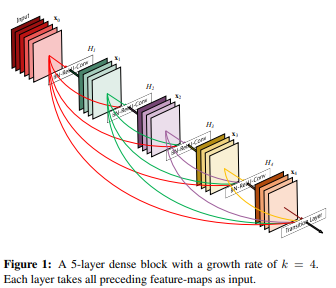
(出所) https://arxiv.org/pdf/1608.06993.pdf (原論文)
原論文の図を示すが、各層間全てに接続がある。
・Batch Norm/Layer Norm/Instance Norm.
<Batch Norm>
ミニバッチに含まれるSampleの同一チャネルが同一分布に従うよう正規化
Batch Sizeが小さい条件下では、学習が収束しないことがあるので、
代わりにLayerNormなどの正規化手法が使わることが多い。
<LayerNorm>
それぞれのsampleの全てのpixelsが同一分布に従うよう正規化
<Instance Norm>
さらにchanelも同一分布に従うよう正規化
・Wavenet
音声生成モデルである。
時系列データに対して畳み込み(Dilated convolution)を適用する。
層が深くなるにつれて畳み込むリンクを離す。
受容野を簡単に増やすことができるという利点がある。
- 実装演習結果キャプチャー又はサマリーと考察:なし
- 「確認テスト」など自分の考察結果
<問題:Mobile Netのアーキテクチャー>
Depthwise Convolutionはチャネルごとに空間方向へ畳み込む。すなわち、チャネルごとにDk×Dk×1のサイズのフィルタをそれぞれ用いて計算を行うため、その計算量は(い)となる。 => H×W×C×K×K
出力Map(H×W×C)のひとますを計算するために、(K×K)の計算が必要。
・入力Map:H×W×C
・カーネル:K×K×1(フィルタ数1)
・出力Map:H×W×C
次に、Depthwise Convolutionの出力をPointwise Convolutionによってチャネル方向に畳み込む。すなわち、出力チャネルごとに1×1×Mサイズのフィルタをそれぞれ用いて計算を行うため、その計算量は(う)となる => H×W×C×M
Cチャネルの入力からMチャネルの出力を得るのに(C×M)の計算が必要。これを出力Mapサイズ(H×W)分計算する。
・入力Map:H×W×C
・カーネル:1×1×C
・出力Map:H×W×M
- 演習問題や参考図書、終了課題など関連記事レポート:なし
<問題:Wavenet>
深層学習を道いて結合確率を学習する際に、効率的に学習が行えるアーキテクチャーを提案したことがWaveNetの大きな貢献の一つである。
提案された新しいConvolution型アーキテクチャーは(あ)と呼ばれ、結合確率を効率的に学習できるようになっている。
・Dilated causal convolution 〇
・Depthwise separable convolution ×(MobileNetの方法)
・Pointwise convolution ×(MobileNetの方法)
・Deconvolution ×(画像の解像度を上げる処理)
Wavenetの利点は、単純なConvolution Layerと比べ、パラメータに対する受容野が広いことである。
Section5:Transformer
- 要点のまとめ
seq2secなどEncoder-Decoder ModelにAttentionを組み合わせる仕掛けがTransformerである。seq2seqでは、入力系列の情報をEncoderで圧縮してから、Decoderに伝えるため、入力系列が長い場合には、Decoderに伝わりにくいとの問題がある。Attention Mechanismはその問題に対処するため、時系列データの中身のそれぞれの関連性に重みをつける手法である。seq2seq+attentionという使われ方をする。
BERT(Bidirectional Encoder Representations from Transformers)はGoogleによって開発された自然言語処理(NLP)の事前学習用のためのTransformerのEncoderを使った機械学習手法である。
- 実装演習結果キャプチャー又はサマリーと考察
lecture_chap2_exercise_public.ipynbの実行結果を表示する。
<学習済みモデルによる生成結果>
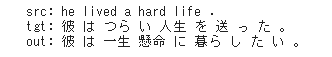




短時間の学習ながら、意味は通じる文章を出力した。
<BLEUの評価>
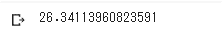
高いスコアであった。
Section6:物体検知・セグメンテーション
- 要点のまとめ
入力画像(カラー/モノクロは問わない)に対する、広義の物体認識タスクは
主に次の4つである。(項目と出力をリストアップする)
- 分類(Classification)
画像に対し単一又は複数のクラスラベル
(物体の位置は問わない)
- 物体検知(Object Detection)
Bounding Box(物体の検出位置)を出力する
(どこに何があるかを出力する)
- 意味領域分割(Semantic Segmentation)
各ピクセルに対する単一のクラスラベル
(物体個々の区別は気にしない)
- 個体領域分割(Instance Segmentation)
各ピクセルに対する単一のクラスラベル
(各物体毎の区別もつけられる)
アルゴリズムの性能評価用に共通の代表的データセットが使用される。
(VOC12、ILSVRC17、MS COCO18、OICOD18)
物体検出においては、クラスラベルと物体位置の予測精度も評価したいので、
IoU:Intersection over Unionの指標が用いられる。
物体検出では、検出精度に加え、検出速度も問題となる。
物体検知のフレームワークの2段階検出と1段階検出の2種類に大別される。
2段階検出とは、候補領域の検出とクラス推定を別々に行う。
(代表フレームワーク:RCNN系)
1段階検出は、候補領域の検出とクラス推定を同時に行う。
(代表フレームワーク:SSD、YOLO、RetinaNetなど)
以上
